Cheat sheet: Keras & Deep Learning layers
Part 0: Intro
Why
Deep Learning is a powerful toolset, but it also involves a steep learning curve and a radical paradigm shift.
For those new to Deep Learning, there are many levers to learn and different approaches to try out. Even more frustratingly, designing deep learning architectures can be equal parts art and science, without some of the rigorous backing found in longer studied, linear models.
In this article, we’ll work through some of the basic principles of deep learning, by discussing the fundamental building blocks in this exciting field. Take a look at some of the primary ingredients of getting started below, and don’t forget to bookmark this page as your Deep Learning cheat sheet!
FAQ
What is a layer?
A layer is an atomic unit, within a deep learning architecture. Networks are generally composed by adding successive layers.
What properties do all layers have?
Almost all layers will have :
- Weights (free parameters), which create a linear combination of the outputs from the previous layer.
- An activation, which allows for non-linearities
- A bias node, an equivalent to one incoming variable that is always set to
1
What changes between layer types?
There are many different layers for many different use cases. Different layers may allow for combining adjacent inputs (convolutional layers), or dealing with multiple timesteps in a single observation (RNN layers).
Difference between DL book and Keras Layers
Frustratingly, there is some inconsistency in how layers are referred to and utilized. For example, the Deep Learning Book commonly refers to archictures (whole networks), rather than specific layers. For example, their discussion of a convolutional neural network focuses on the convolutional layer as a sub-component of the network.
1D vs 2D
Some layers have 1D and 2D varieties. A good rule of thumb is:
- 1D: Temporal (time series, text)
- 2d: Spatial (image)
Cheat sheet
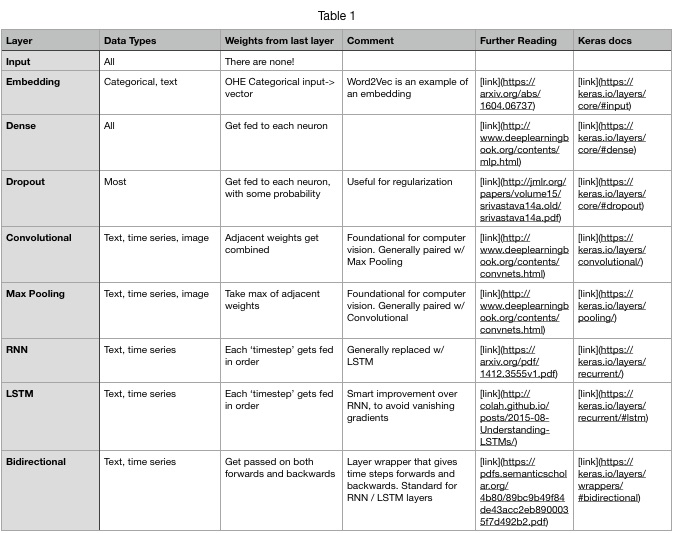
Part 1: Standard layers
Input
- Simple pass through
- Needs to align w/ shape of upcoming layers
Embedding
- Categorical / text to vector
- Vector can be used with other (linear) algorithms
- Can use transfer learning / pre-trained embeddings(see example)
Dense layers
- Vanilla, default layer
- Many different activations
- Probably want to use ReLu activation
Dropout
- Helpful for regularization
- Generally should not be used after input layer
- Can select fraction of weights (
p) to be dropped - Weights are scaled at train / test time, so average weight is the same for both
- Weights are not dropped at test time
Part 2: Specialized layers
Convolutional layers
- Take a subset of input
- Create a linear combination of the elements in that subset
- Replace subset (multiple values) with the linear combination (single value)
- Weights for linear combination are learned
Time series & text layers
- Helpful when input has a specific order
- Time series (e.g. stock closing prices for 1 week)
- Text (e.g. words on a page, given in a certain order)
- Text data is generally preceeded by an embedding layer
- Generally should be paired w/
RMSpropoptimizer
Simple RNN
- Each time step is concatenated with the last time step's output
- This concatenated input is fed into a dense layer equivalent
- The output of the dense layer equivalent is this time step's output
- Generally, only the output from the last time step is used
- Specially handling for the first time step
LSTM
- Improvement on Simple RNN, with internal 'memory state'
- Avoid issue of exploding / vanishing gradients
Utility layers
- There for utility use!